借口 那是一个夜黑风高的晚上,楼主正在整理东芝2T硬盘,在一个角落里发现一个小小的视频,点击一看映入眼前的是图1,后面就是看了会让人赤面耳红的画面,嗯哼!“澳门首家线上赌场上线啦!@#¥%……&”,接着就是这次文章的主要角色,@#¥%论坛(宣传画面上的链接)
注意 为了不必要的麻烦,本文中所有文字和图片及链接都经过处理,但保持原网站的结构
为了不必要的麻烦,本文中所有文字和图片及链接都经过处理,但保持原网站的结构
为了不必要的麻烦,本文中所有文字和图片及链接都经过处理,但保持原网站的结构
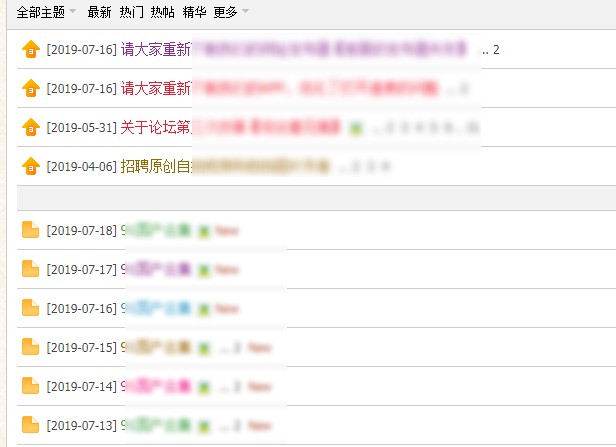
列表 论坛采用的典型的Discuz! X3.4程序建的,板块太多,随便点了几个就让人不能镇定自若,本着学习的态度分析了其中一个板块
板块的名称叫【原创BT电影】,是提供BT种子类型的,也利于我们用Python抓取,点了其中了【亚洲有码原创】,真的是因为文字太具有色情性质,换了一个相对而言比较好的板块截图,但是框架结构是一样的。
【“假”亚洲有码原创】大概长这个样子,要抓取的知识其中的非置顶 部分
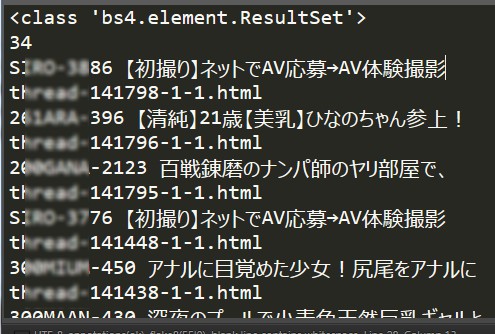
审核元素,发现置顶和非置顶都在一个table中,每一条信息里面的id,呈现某种我未发现的规律,怎么办法?去除呗,首先想到的是求差集,在a中但不在b中;把a中的b去除。我要的操作就是将b进行收集(参考1)
1 2 3 def diff (listA,listB ): return list (set (listA).difference(set (listB)))
但是我在实际应用中并没有用到,打印类型好像不对,理论上是可行的。我用的是另外一种方法——判断,即在遍历链接列表的时候加个判断,原理和差集相似。
1 2 3 4 5 url_list_b = ['thread-141587-1-1.html' ,'thread-141585-1-1.html' ,'thread-126525-1-1.html' ,'thread-126525-1-1.html' ] for item in url_list: temp_url = item.attrs['href' ] if temp_url not in url_list_b:
对于链接列表要获取的只有【地址】,链接名(链接标题)可有可无,因为在页面里面也是可以获取具体的标题的,我还是获取下链接名。链接也是有特点的,那便是 class为“s xst”,如此遍简单了。
1 url_list = bsObj.find_all('a' ,{'class' :'s xst' })
遍历全部的链接
1 2 3 4 5 for item in url_list: temp_url = item.attrs['href' ] if temp_url not in url_list_b: print (item.get_text()) print (temp_url)
遍历效果
接下来则是获取具体的电影信息即可。
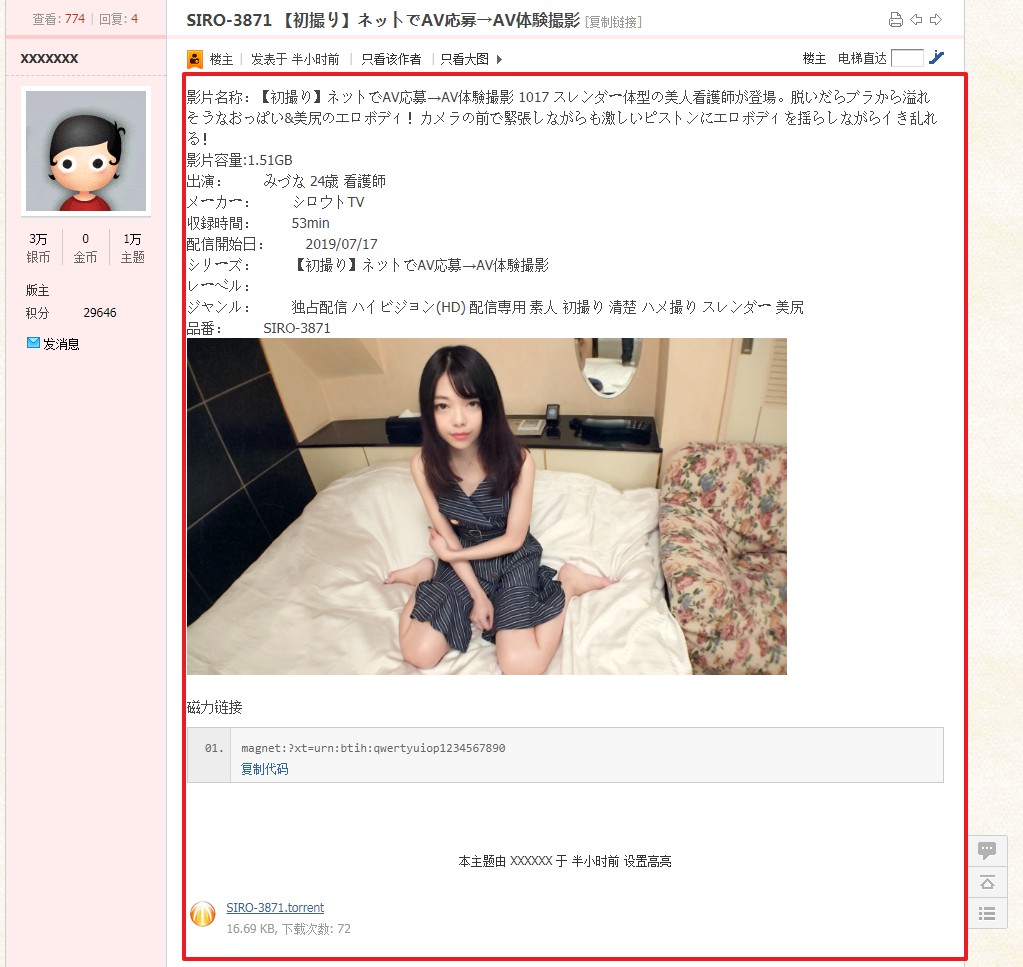
页面 点开某个链接,页面大概长这个样子(处理过)
我提取了楼主发布的全部信息的html源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 <div class ="t_fsz" > <table cellspacing ="0" cellpadding ="0" > <tbody > <tr > <td class ="t_f" id ="postmessage_752937" > 影片名称:【初撮り】ネットでAV応募→AV体験撮影 1017 スレンダー体型の美人看護師が登場。脱いだらブラから溢れそうなおっぱい& 美尻のエロボディ!カメラの前で緊張しながらも激しいピストンにエロボディを揺らしながらイき乱れる!<br > 影片容量:1.51GB<br > 出演: みづな 24歳 看護師<br > メーカー: シロウトTV<br > 収録時間: 53min<br > 配信開始日: 2019/07/17<br > シリーズ: 【初撮り】ネットでAV応募→AV体験撮影<br > レーベル: <br > ジャンル: 独占配信 ハイビジョン(HD) 配信専用 素人 初撮り 清楚 ハメ撮り スレンダー 美尻<br > 品番: SIRO-3871<br > <img id ="aimg_I4ET5" onclick ="zoom(this, this.src, 0, 0, 0)" class ="zoom" file ="https://image.mgstage.com/images/shirouto/siro/3871/pb_e_siro-3871.jpg" onmouseover ="img_onmouseoverfunc(this)" lazyloadthumb ="1" border ="0" alt ="" src ="https://image.mgstage.com/images/shirouto/siro/3871/pb_e_siro-3871.jpg" lazyloaded ="true" width ="600" height ="337" style ="cursor: pointer;" > <br > <br > 磁力链接<br > <div class ="blockcode" > <div id ="code_Ec2" > <ol > <li > magnet:?xt=urn:btih:qwertyuiop1234567890</li > </ol > </div > <em onclick ="copycode($('code_Ec2'));" > 复制代码</em > </div > <br > </td > </tr > </tbody > </table > <div class ="modact" > <a href ="forum.php?mod=misc& action=viewthreadmod& tid=142117" title ="帖子模式" onclick ="showWindow('viewthreadmod', this.href)" > 本主题由 XXXXXX 于 <span title ="2019-07-18 10:42" > 半小时前</span > 设置高亮</a > </div > <div class ="pattl" > <ignore_js_op > <dl class ="tattl" > <dt > <img src ="static/image/filetype/torrent.gif" border ="0" class ="vm" alt ="" > </dt > <dd > <p class ="attnm" > <a href ="forum.php?mod=attachment& aid=MTkyNzgyfDhmMDdkOGI3fDE1NjM0MjA0ODJ8MHwxNDIxMTc%3D" onmouseover ="showMenu({'ctrlid':this.id,'pos':'12'})" id ="aid192782" target ="_blank" initialized ="true" > SIRO-3871.torrent</a > </p > <div class ="tip tip_4" id ="aid192782_menu" style ="position: absolute; z-index: 301; left: 693.5px; top: 1444px; display: none;" disautofocus ="true" initialized ="true" > <div class ="tip_c" > <p class ="y" > <span title ="2019-07-18 10:40" > 半小时前</span > 上传</p > <p > 点击文件名下载附件</p > </div > <div class ="tip_horn" > </div > </div > <p > </p > <p > 16.69 KB, 下载次数: 72</p > <p > </p > </dd > </dl > </ignore_js_op > </div > </div >
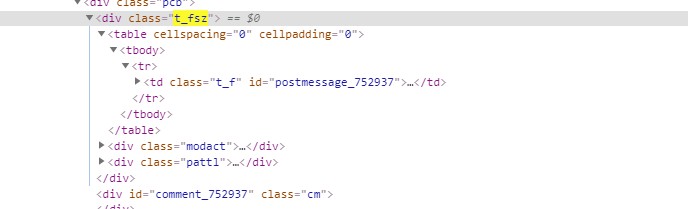
又是这样一大段文字,没有任何id或者class,之前的几个爬虫我都是尽量避免和他们相见的
但是想起之前看的一篇爬虫文章有处理过类似的文字(参考2)其核心函数只有一个
又搜索了下 startswith 这函数得知(参考3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Python3 startswith()方法 Python3 字符串 Python3 字符串 描述 startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。如果参数 beg 和 end 指定值,则在指定范围内检查。 语法 startswith()方法语法: str.startswith(substr, beg=0,end=len(string)); 参数 str -- 检测的字符串。 substr -- 指定的子字符串。 strbeg -- 可选参数用于设置字符串检测的起始位置。 strend -- 可选参数用于设置字符串检测的结束位置。 返回值 如果检测到字符串则返回True,否则返回False。
如此一来一大段文字也不是没有解决的办法了,先将其字符串替换成统一,去掉不必要的字符,最后再分组即可。我在其中还发现了一个有意思的地方那便是中文,英文,日文状态下的冒号完全不同,中英还好理解,日文也特别还是第一次见.
电影信息也是分为两个部分处理的,其1则是信息介绍,图片,磁力链接(至上到下),其2则是后来发现种子也是可以下载。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 html.encoding = 'utf-8' bsObj = BeautifulSoup(html.text,'lxml' ) if bsObj.title: b = bsObj.find('td' ,{'class' :'t_f' }) c = b.get_text().replace(':' ,':' ).replace(':' ,':' ).replace('\r' ,'' ).split("\n" ) torrent = b.select('a[target="_blank"]' ) if torrent: torrent = torrent[0 ].attrs['href' ] image = b.find_all('img' ) images = [] for item in image: images.append(item.attrs['file' ]) movie_info = {} for item in c: if item.startswith('影片名称:' ): movie_info['name' ] = item.replace('影片名称:' ,"" ) if item.startswith('影片容量:' ): movie_info['size' ] = (item.replace('影片容量:' ,"" )) if item.startswith('出演:' ): movie_info['star' ] = (item.replace('出演: ' ,"" )) if item.startswith('収録時間:' ): movie_info['Rtime' ] = (item.replace('収録時間: ' ,"" )) if item.startswith('シリーズ:' ): movie_info['series' ] = (item.replace('シリーズ: ' ,"" )) if item.startswith('レーベル:' ): movie_info['lable' ] = (item.replace('レーベル: ' ,"" )) if item.startswith('ジャンル:' ): movie_info['schools' ] = (item.replace('ジャンル: ' ,"" )) if item.startswith('品番:' ): movie_info['code' ] = (item.replace('品番: ' ,"" )) if item.startswith('magnet:' ): movie_info['magnet' ] = (item.replace('复制代码' ,"" )) if item.startswith('磁力链接 ' ): movie_info['magnet' ] = (item.replace('复制代码' ,"" ).replace('磁力链接 ' ,'' )) movie_info['torrent' ] = 'https://www.baidu.com/' +torrent movie_info['images' ] = images
和参考2不同的是我是直接获取text之后在进行处理,所以对空格 用 是不能替换的,尝试过加双引号也未果,便只能用复制空格替换了,其实trim应该也是可以的吧。
最终运行结果(演示,只抓取一个链接)
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 import requestsimport refrom bs4 import BeautifulSoupdef diff (listA,listB ): return list (set (listA).difference(set (listB))) def get_page (url,movie_list ): headers = {'user-agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' } proxies = {"http" : "http://127.0.0.1:1080" , "https" : "127.0.0.1:1080" } html = requests.get(url,headers=headers, proxies=proxies) try : html.encoding = 'utf-8' bsObj = BeautifulSoup(html.text,'lxml' ) url_list = bsObj.find_all('a' ,{'class' :'s xst' }) print (str (type (url_list))) print (len (url_list)) url_list_b = ['thread-141587-1-1.html' ,'thread-141585-1-1.html' ,'thread-126525-1-1.html' ,'thread-101886-1-1.html' ] for item in url_list: temp_url = item.attrs['href' ] if temp_url not in url_list_b: print (item.get_text()+'----正在获取中' ) movie_list.append(html_de_link('https://www.baidu.com/' +temp_url)) print ('----成功捕获一只小姐姐----' ) except ArithmeticError as e: return None def html_de_link (url ): headers = {'user-agent' : 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36' } proxies = {"http" : "http://127.0.0.1:1080" , "https" : "127.0.0.1:1080" } html = requests.get(url,headers=headers, proxies=proxies) try : html.encoding = 'utf-8' bsObj = BeautifulSoup(html.text,'lxml' ) if bsObj.title: b = bsObj.find('td' ,{'class' :'t_f' }) c = b.get_text().replace(':' ,':' ).replace(':' ,':' ).replace('\r' ,'' ).split("\n" ) torrent = b.select('a[target="_blank"]' ) if torrent: torrent = torrent[0 ].attrs['href' ] image = b.find_all('img' ) images = [] for item in image: images.append(item.attrs['file' ]) movie_info = {} for item in c: if item.startswith('影片名称:' ): movie_info['name' ] = item.replace('影片名称:' ,"" ) if item.startswith('影片容量:' ): movie_info['size' ] = (item.replace('影片容量:' ,"" )) if item.startswith('出演:' ): movie_info['star' ] = (item.replace('出演: ' ,"" )) if item.startswith('収録時間:' ): movie_info['Rtime' ] = (item.replace('収録時間: ' ,"" )) if item.startswith('シリーズ:' ): movie_info['series' ] = (item.replace('シリーズ: ' ,"" )) if item.startswith('レーベル:' ): movie_info['lable' ] = (item.replace('レーベル: ' ,"" )) if item.startswith('ジャンル:' ): movie_info['schools' ] = (item.replace('ジャンル: ' ,"" )) if item.startswith('品番:' ): movie_info['code' ] = (item.replace('品番: ' ,"" )) if item.startswith('magnet:' ): movie_info['magnet' ] = (item.replace('复制代码' ,"" )) if item.startswith('磁力链接 ' ): movie_info['magnet' ] = (item.replace('复制代码' ,"" ).replace('磁力链接 ' ,'' )) movie_info['torrent' ] = 'https://www.baidu.com/' +torrent movie_info['images' ] = images return movie_info except ArithmeticError as e: print (e) if __name__ == '__main__' : movie_list=[] for i in range (1 ,2 ): get_page('https://www.baidu.com/forum-37-' +str (i)+'.html' ,movie_list) print (movie_list)
问题
昨天(7-17)写的时候出现日语乱码的现象,今天再试未能复现
网站需要爱国上网,参考4
网站访问是真的慢,索性保存列表和页面,本地使用php server来测试
cmd在目录下运行php -S localhost:8080,需要php全局变量
电影信息完全没有必要,只要获取 品番 和预览图即可,信息则是本着学习的态度去获取
最后
本文和代码属于纯学习性质研究
如果你通过脚本抓取了类似的信息,资源请一定要符合《当地国家地区法律法规》的情况下使用。
北京第三区交通委提醒您:道路千万条,安全第一条。飙车一时爽,一直飙一直爽。
参考
@bitcarmanlee - python 两个list 求交集,并集,差集 - bitcarmanlee的博客 - CSDN博客 @Dwyane_Coding - Python爬取电影天堂 - 掘金 Python3 startswith()方法 | 菜鸟教程 高级用法 — Requests 2.18.1 文档